✔ Using preferred font, ITC Franklin Gothic.
ℹ Specify a different font to use with 360info themes by calling
register_360fonts() or by setting options("themes360info.franklin.pref") to
either "itc" or "libre" (or "none" to disable automatic font loading).
Code
library(ggtext)register_360fonts("libre")
✔ Using preferred font, Libre Franklin.
ℹ Specify a different font to use with 360info themes by calling
register_360fonts() or by setting options("themes360info.franklin.pref") to
either "itc" or "libre" (or "none" to disable automatic font loading).
We’ll use their Bulk Data Download Service to acquire the data quickly, but we’re particularly interested in the indicators within the Education theme labelled Number and rates of international mobile students (inbound and outbound).
Code
library(pins)# create /data/.cachedata_cache <-here("data", ".cache")dir.create(data_cache, showWarnings =FALSE)# download the zip file (keeping it cached if we redo this)zipped_data <-board_url(c(opri =paste0("https://apimgmtstzgjpfeq2u763lag.blob.core.windows.net/","content/MediaLibrary/bdds/OPRI.zip")),cache = data_cache) %>%pin_download("opri")# unzip it unzip(zipped_data, exdir = data_cache)# read the coding sheets incountry_map <-read_csv(file.path(data_cache, "OPRI_COUNTRY.csv"), col_types ="cc")indicator_map <-read_csv(file.path(data_cache, "OPRI_LABEL.csv"),col_types ="cc")region_map <-read_csv(file.path(data_cache, "OPRI_REGION.csv"), col_types ="ccc")# read the data innational_data <-read_csv(file.path(data_cache, "OPRI_DATA_NATIONAL.csv"),col_types ="ccincc")
Tidying and joining the origin data
This data is two dimensional, in a way: there’s the country students go from (that is, the origin) and the country that go to (the destination). The way the data is organised into indicators by origin ("[continent]: "Students from" [country], both sexes (number)"), and within that indicator there’s a row for each destination, each year.
So you can easily look up where a country’s students have gone. If you want to look up where a country’s students have come from, though, you would need to tally up the destination row for a country in every origin indicator. That’s what we’re going to do (with the implicit assumption that there are no countries missing).
Map preparation
The national data already has a destination column. It also has an indicator number column, and we need to map that back to a country code using the label map and the country map.
Code
# first, isolate the continent and country of originindicator_map %>%filter(str_detect(INDICATOR_LABEL_EN, "Students from")) %>%mutate(INDICATOR_LABEL_EN =str_replace(INDICATOR_LABEL_EN,fixed(", both sexes (number)"), ""),INDICATOR_LABEL_EN =str_replace(INDICATOR_LABEL_EN,fixed(" Students from "), "")) %>%separate(INDICATOR_LABEL_EN, into =c("continent", "country"), sep =":") %>%# some indicators also preface country name with "the "mutate(country =str_replace(country, "^the ", "")) ->tidy_origins# now match these to the country maptidy_origins %>%left_join(country_map, by =c("country"="COUNTRY_NAME_EN")) %>%# we'll use {countrycode} as a backup for the un country list,# since they aren't always entirely consistentmutate(countrycode_backup =countrycode(country,origin ="country.name", destination ="iso3c"),code =coalesce(COUNTRY_ID, countrycode_backup)) %>%select(INDICATOR_ID, continent,country_name = country,country_code = code) %>%# finally, let's neaten a few country names up# mutate(l = nchar(country_name)) %>% arrange(desc(l)) %>%# select(country_name, country_code, l)mutate(country_name =case_when( country_code =="HKG"~"Hong Kong", country_code =="MAC"~"Macao", country_code =="PRK"~"North Korea", country_code =="COD"~"DR Congo", country_code =="VCT"~"St Vincent/Grenadines", country_code =="VEN"~"Venezuala", country_code =="LAO"~"Laos", country_code =="BOL"~"Bolivia", country_code =="FSM"~"Micronesia", country_code =="TZA"~"Tanzania", country_code =="IRN"~"Iran", country_code =="RUS"~"Russia", country_code =="MDA"~"Moldova", country_code =="SYR"~"Syria",TRUE~ country_name)) %>%write_csv(here("data", "country-names.csv")) ->indicator_origin_map
Warning in countrycode_convert(sourcevar = sourcevar, origin = origin, destination = dest, : Some values were not matched unambiguously: Netherlands Antilles, Sudan (pre-secession), unknown countries
Note that we still have a few unmapped country codes: those cases where the origin continent is known but not the country:
Now we’re ready to map these codes back onto the national data:
Code
national_data %>%select(INDICATOR_ID, dest_country_code = COUNTRY_ID, year = YEAR,value = VALUE, magnitude = MAGNITUDE, qualifier = QUALIFIER) %>%# join the origin map infilter(INDICATOR_ID %in% indicator_origin_map$INDICATOR_ID) %>%left_join(indicator_origin_map, by ="INDICATOR_ID") %>%rename(origin_continent = continent, origin_country_name = country_name,origin_country_code = country_code) %>%# now we're going to join it _again_, but this time to get the _destination_# name and continentleft_join(indicator_origin_map,by =c("dest_country_code"="country_code")) %>%rename(dest_continent = continent, dest_country_name = country_name) %>%# add continent to "unknown countries" binsmutate(origin_country_name =if_else(str_detect(origin_country_name, "unknown countries"),paste0(origin_continent, ": unknown countries"), origin_country_name),# a few us territories aren't on the origin map, so let's fill them in again# for the destination listdest_country_name =coalesce(dest_country_name,countrycode(dest_country_code, "iso3c", "country.name"))) %>%select(starts_with("origin"), starts_with("dest"), year, value, magnitude, qualifier) %>%write_csv(here("data", "student-flows-tidy.csv")) ->national_data_joined
Warning in countrycode_convert(sourcevar = sourcevar, origin = origin, destination = dest, : Some values were not matched unambiguously: ANT, XDN
Before we start visualising, let’s now break this back into data by origin and by destination. That way, we can lump all the same values together and make a more compact statement about the main comings and goings for a given country.
Code
# most popular destinations for each originnational_data_joined %>%filter(!is.na(value), value >0) %>%group_by(year, origin_country_name) %>%mutate(dest_country_lumped =fct_lump_n(f = dest_country_name, n =10, w = value,other ="Other countries")) %>%ungroup() %>%# now add up all the lumped onesselect(origin_country_name, dest_country_lumped, year, value, magnitude, qualifier) %>%group_by(year, origin_country_name, dest_country_lumped) %>%summarise(value_lumped =sum(value, na.rm =TRUE),# also format labels for qualifierscond_includes =if_else(any(magnitude =="INCLUDES", na.rm =TRUE), "a", "-"),cond_included =if_else(any(magnitude =="INCLUDED", na.rm =TRUE), "b", "-"),cond_natest =if_else(any(qualifier =="NAT_EST", na.rm =TRUE), "c", "-"),cond_uisest =if_else(any(qualifier =="UIS_EST", na.rm =TRUE), "d", "-"),cond_all =str_trim(paste(cond_includes, cond_included, cond_natest, cond_uisest, collapse =","))) %>%ungroup() %>%select(year, origin_country_name, dest_country_lumped, value_lumped, cond_all) %>%write_csv(here("data", "popular-destinations-by-origin.csv")) ->popular_destinations
`summarise()` has grouped output by 'year', 'origin_country_name'. You can
override using the `.groups` argument.
Code
# most popular origins for each destinationnational_data_joined %>%filter(!is.na(value), value >0) %>%group_by(year, dest_country_name) %>%mutate(origin_country_lumped =fct_lump_n(f = origin_country_name, n =10, w = value,other ="Other countries")) %>%ungroup() %>%# now add up all the lumped onesselect(dest_country_name, origin_country_lumped, year, value, magnitude, qualifier) %>%group_by(year, dest_country_name, origin_country_lumped) %>%summarise(value_lumped =sum(value, na.rm =TRUE),# also format labels for qualifierscond_includes =if_else(any(magnitude =="INCLUDES", na.rm =TRUE), "a", "-"),cond_included =if_else(any(magnitude =="INCLUDED", na.rm =TRUE), "b", "-"),cond_natest =if_else(any(qualifier =="NAT_EST", na.rm =TRUE), "c", "-"),cond_uisest =if_else(any(qualifier =="UIS_EST", na.rm =TRUE), "d", "-"),cond_all =str_trim(paste(cond_includes, cond_included, cond_natest, cond_uisest, collapse =","))) %>%ungroup() %>%select(year, dest_country_name, origin_country_lumped, value_lumped, cond_all) %>%write_csv(here("data", "popular-origins-by-destination.csv")) ->popular_origins
`summarise()` has grouped output by 'year', 'dest_country_name'. You can
override using the `.groups` argument.
Code
# list of countriesc( national_data_joined$origin_country_name, national_data_joined$dest_country_name) %>%unique() %>%discard(is.na) %>%tibble(name = .) %>%write_csv(here("data", "country-list.csv"))
Visualisation: single country flows
Let’s start by looking at who comes from and to any given country.
Let’s also bring Human Development Index data in to compare against. Our World in Data has the tidiest version of this:
Code
# from https://hdr.undp.org/en/indicators/137506# via https://ourworldindata.org/human-development-index# but not iso3c codes!read_csv(here("data", "hdi-owid.csv")) %>%set_names(c("country_name", "country_code", "year", "hdi")) ->hdi
Rows: 5001 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): Entity, Code
dbl (2): Year, Human Development Index (UNDP)
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Code
# join the net flow data with owid hdi datanetflows %>%left_join(hdi, by =c("country_code", "year"), suffix =c(".uis", ".owid")) %>%mutate(country_name =coalesce(country_name.uis, country_name.owid)) %>%select(year, continent, country_code, country_name, flow_value, flow_ratio, hdi) ->netflows_hdi
Code
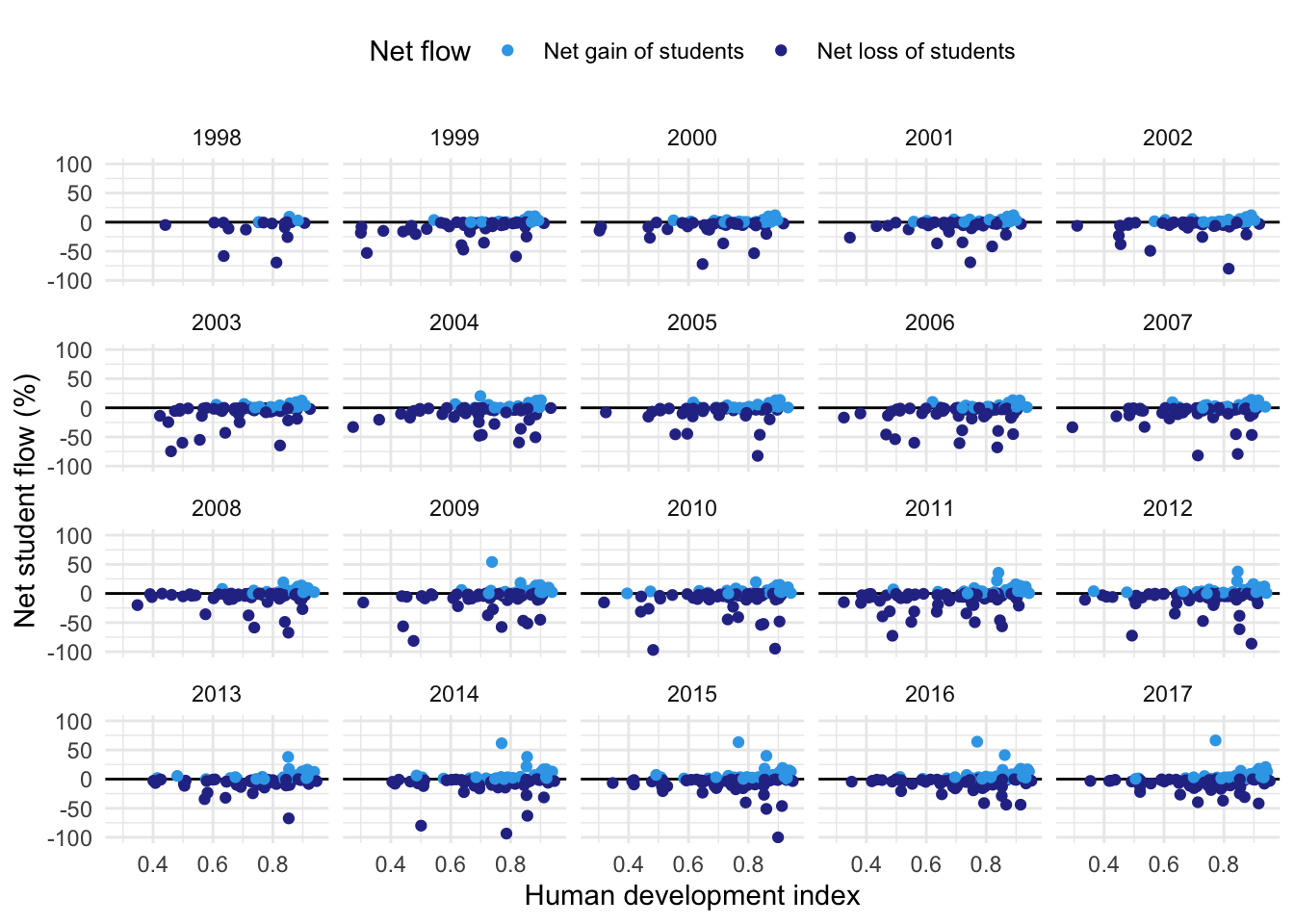
netflows_hdi %>%filter(!is.na(flow_ratio), !is.na(hdi)) %>%mutate(flow_sign =if_else(flow_ratio >=0,"Net gain of students","Net loss of students")) %>% {ggplot(.) +aes(x = hdi, y = flow_ratio, colour = flow_sign) +geom_hline(yintercept =0) +geom_point() +scale_colour_manual(values =unname(colours_360("blues"))) +facet_wrap(vars(year)) +ylim(c(-100, 100)) +theme_minimal() +theme(legend.position ="top",legend.direction ="horizontal") +labs(x ="Human development index",y ="Net student flow (%)",colour ="Net flow") }
It seems that a subset of high-HDI countries (not all) are the ones that tend to receive students.
Net flow map
These indicators tell us the net flow in or out of any given country, but I’d really like to know the net flow across any pair of countries. Let’s return to the country-to-country data, national_data_joined, and try to work that out.
First, let’s get the spatial data (country centroids) needed to make a map. I first used {rnaturalearth} for this, but I found CoordinateCleaner (which uses the CIA Fact Book) to be considerably more complete:
I’d been hoping to simplify any network visualisation of student flows by only showing the net flow between any two countries.
Unfortunately, the data isn’t quite good enough for this. The below code pivots the network of student flows to try and calculate net flow, but there’s enough data missing that you’re losing a large part of it by requiring both sides (in other words, if either country’s departing flow is NA, so is the net flow).
Nevertheless, the code is below for reproduction purposes!
Code
national_data_joined %>%select(year, origin = origin_country_code, dest = dest_country_code, value, magnitude, qualifier) %>%filter(!is.na(origin), !is.na(dest)) %>%# now create a two-country key and direction for the pivotmutate(direction =if_else(origin < dest, "toB", "toA"),pairkey =paste(pmin(origin, dest), pmax(origin, dest), sep ="_")) %>%pivot_wider(id_cols =c(pairkey, year), names_from = direction,values_from =c(value, magnitude, qualifier)) %>%separate(pairkey, into =c("countryA", "countryB")) %>%# ditch the extra country columnsselect(year, countryA, countryB,starts_with("value"),starts_with("magnitude"),starts_with("qualifier")) %>%# calculate net flowmutate(netflow =abs(value_toB - value_toA),net_destination =if_else( value_toB > value_toA, countryB, countryA)) %>%write_csv(here("data", "tidy-countrypair-netflows.csv")) ->countrypair_netflows
Flow maps
Let’s return to showing all the student flows. This will be messy, but some judicious use of opacity might make things clearer.
Code
# bring the country centroid and hdi info in and create lines between countries# (this is a bit colvoluted but was the only performant solution i could find to# creating two-point linestrings)# (also note that {CoordinateCleaner}'s points appear to be Y/X rather than X/Y.# this code is a little weird to read as a result)national_data_joined %>%left_join(country_centroids,by =c("origin_country_code"="country_code")) %>%left_join(select(hdi, -country_name),by =c("year", "origin_country_code"="country_code")) %>%rename(origin_pt = geometry, origin_hdi = hdi) %>%left_join(country_centroids,by =c("dest_country_code"="country_code")) %>%left_join(select(hdi, -country_name),by =c("year", "dest_country_code"="country_code")) %>%rename(dest_pt = geometry, dest_hdi = hdi) %>%# extract pt coordinates out to colsfilter(!st_is_empty(origin_pt), !st_is_empty(dest_pt)) %>%mutate(origin_coord =st_coordinates(origin_pt),dest_coord =st_coordinates(dest_pt),# (note flipping X and Y because {CoordinateCleaner}'s points are around the# wrong way)origin_lat = origin_coord[, "X"],origin_lon = origin_coord[, "Y"],dest_lat = dest_coord[, "X"],dest_lon = dest_coord[, "Y"]) %>%mutate(path =pmap(select(., origin_lon, origin_lat, dest_lon, dest_lat),~st_linestring(matrix(c(..1, ..2, ..3, ..4), ncol =2, byrow =TRUE))),path =st_sfc(path)) ->flows_all_dfflows_all_df %>%select(-ends_with("lon"), -ends_with("lat"), -ends_with("coord")) %>%st_as_sf(crs =st_crs(4326), sf_column_name ="path") ->flows_all# write out to disk for gis work (not version controlled)st_write(flows_all, here("data", "flows_all.gpkg"), delete_dsn =TRUE)
Warning in clean_columns(as.data.frame(obj), factorsAsCharacter): Dropping
column(s) origin_pt,dest_pt of class(es) sfc_POINT;sfc,sfc_POINT;sfc
Deleting source `/Users/jgol0005/Code/report-global-education/data/flows_all.gpkg' failed
Writing layer `flows_all' to data source
`/Users/jgol0005/Code/report-global-education/data/flows_all.gpkg' using driver `GPKG'
Writing 410981 features with 12 fields and geometry type Line String.
Grouped country flows
Let’s group our countries by HDI and work out the flows between those groups each year
`summarise()` has grouped output by 'year', 'origin_hdi_bin'. You can override
using the `.groups` argument.
Code
flows_hdigroups %>%filter(between(year, 2008, 2017)) %>%# get annual averagegroup_by(origin_hdi_bin, dest_hdi_bin) %>%summarise(avg_students =mean(students, na.rm =TRUE)) %>%ungroup() %>%mutate(origin_hdi_bin =recode(origin_hdi_bin,"Low"="Low\nHDI less than 70%","Medium"="Medium\nHDI 70% to 85%","High"="High\nHDI over 85%")) %>%print() %>% {ggplot(.) +aes(y = avg_students, axis1 = origin_hdi_bin, axis2 = dest_hdi_bin) +geom_alluvium(aes(fill = dest_hdi_bin)) +geom_stratum(aes(fill = dest_hdi_bin),colour =NA) +geom_text(stat ="stratum", aes(label =after_stat(stratum)),family ="Body 360info", colour ="white", size =4.5) +scale_y_continuous(labels = scales::label_number_si(accuracy =1),sec.axis =dup_axis(),expand =expansion(mult =c(0, 0.125))) +scale_fill_manual(values =c("Low"="#10bd69", "Medium"="#2542b8", "High"="#fc4a12"),guide =NULL) +# label origin/destination columnsannotate_360_glasslight(x =1, y =Inf, label ="Origin<br>economy",vjust ="inward", fontface ="bold", size =6) +annotate_360_glasslight(x =2, y =Inf, label ="Destination<br>economy",vjust ="inward", fontface ="bold", size =6) +theme_360() +theme(panel.grid.minor =element_blank(),panel.grid.major =element_blank(),axis.text.x =element_blank(),# axis.ticks.y = element_line(),axis.title.y.right =element_blank(),plot.margin =margin(10, 10, 10, 10),plot.subtitle =element_markdown(family ="Body 360info",face ="plain") ) +labs(x =NULL, y ="Average number of visiting students per year",title =toupper("Student flows 2008–2017"),subtitle =paste("Although students come from economies across the development spectrum,","they tend to visit **highly developed economies** to study.",sep ="<br>"),caption =paste("**CHART:** James Goldie, 360info","**DATA:** UN Institute of Statistics, Our World in Data",sep ="<br>")) } %>%save_360plot(here("out", "student-flows-hdigroups.png"),shape ="square") %>%save_360plot(here("out", "student-flows-hdigroups.svg"),shape ="square")
`summarise()` has grouped output by 'origin_hdi_bin'. You can override using the
`.groups` argument.
# A tibble: 9 × 3
origin_hdi_bin dest_hdi_bin avg_students
<fct> <fct> <dbl>
1 "Low\nHDI less than 70%" Low 107708.
2 "Low\nHDI less than 70%" Medium 226533.
3 "Low\nHDI less than 70%" High 619061.
4 "Medium\nHDI 70% to 85%" Low 22779.
5 "Medium\nHDI 70% to 85%" Medium 289125.
6 "Medium\nHDI 70% to 85%" High 1049024.
7 "High\nHDI over 85%" Low 8491.
8 "High\nHDI over 85%" Medium 59578.
9 "High\nHDI over 85%" High 693972.